In the ACTIVE study, we have data on verbal ability at two times (hvltt and hvltt2). To investigate the relationship between them, we can generate a scatterplot using hvltt and hvltt2 as shown below. From the plot, it is easy to observe that those with a higher score on hvltt tend to have a higher score on hvltt2. Certainly, it is not difficult to find two people where the one with higher score on hvltt has a lower score on hvltt2. But in general hvltt and hvltt2 tend to go up and down together.
Furthermore, the association between hvltt and hvltt2 seems to be able to be described by a straight line. The red line in the figure is one that run across the points in the scatter plot. The straight line can be expressed using
\[hvltt2 = 5.19 + 0.73*hvltt\]
It says multiplying one's test score (hvltt) at the first occasion by 0.73 and adding 5.19 predict his/her test score (hvltt2) at the second occasion.
A regression model / regression analysis can be used to predict the value of one variable (the dependent or outcome variable) on the basis of other variables (the independent and predictor variables). Typically, we use \(y\) to denote the dependent variable and \(x\) to denote an independent variable.
The simple linear regression model for the population can be written as
\[y = \beta_0 + \beta_1 x + \epsilon\]
where
\(\beta_0\) is called the intercept, which is also the average value of \(y\) when \(x=0\).
\(\beta_1\) is called the slope, which is the change in \(y\) given the unit change in \(x\). Therefore, it is also called rate of change.
\(\epsilon\) is a normal error that is often assumed to have a normal distribution with mean 0 and unknown variance \(\sigma^2\). This term represents the part of information in \(y\) that cannot be explained by \(x\).
Parameter estimation
In practice, the population parameters $\beta_0$ and $\beta_1$ are unknown. However, with a set of sample data, they can be estimated. One often used estimation method for regression analysis is called least squares estimation method. We explain the method here.
Let the model below represent the estimated regression model:
\[ y = b_0 + b_1 x + e \]
where
\(b_0\) is an estimate of the population intercept \(\beta_0\)
\(b_1\) is an estimate of the population slope \(\beta_1\)
\(e\) is the residual, which estimate \(\epsilon\).
Assume we already get the estimates \(b_0\) and \(b_1\), then we can make a prediction of the value of \(y\) based on the value of \(x\). For example, for the \(i\)th participant, if his/her score on the independent variable is \(x_i\), then the corresponding predicted outcome \(\hat{y}_i\) based on the regression model is
\[\hat{y}_i = b_0 + b_1 x_i.\]
The difference between the predicted value and the observed data for this participant, also called the prediction error, is
\(e_i = y_i - \hat{y}_i\).
The parameter \(b_0\) and \(b_1\) potentially can take any values. A good choice could be those that make the errors smallest, which leads to the least squares estimation.
Least squares estimation
The least squares estimation obtains \(b_0\) and \(b_1\) by minimizing the sum of the squared prediction errors. Therefore, such a set of parameters makes \(\hat{y}_i\) closest to \(y_i\) on average. Specifically, one minimizes SSE as
where \(\bar{x} = \sum_{i=1}^{n} x_i / n\) and \(\bar{y} = \sum_{i=1}^{n} y_i / n\).
Hypothesis testing
If no linear relationship exists between the two variables, we would expect the regression line to be horizontal, that is, to have a slope of zero. Therefore, we can test whether the hypothesis that the population regression slope is 0. More specifically, we have the null hypothesis
\[ H_0: \beta_1 = 0.\]
And the alternative hypothesis is
\[ H_1: \beta_1 \neq 0.\]
To conduct the hypothesis testing, we calculate a t test statistic
\[ t = \frac{b_1 - \beta_1}{s_{b_1}} \]
where \(s_{b_1}\) is the standard error of \(b_1\).
If \(\beta_1 = 0\) in the population, then the statistic t follows a t-distribution with degrees of freedom \(n-2\).
Regression in R
Both the parameter estimates and the t test can be conducted using an R function lm().
An example
To show how to conduct a simple linear regression, we analyze the relationship between hvltt and hvltt2 from the ACTIVE study. The R input and output for the regression analysis is given below.
Within the function lm(), the first required input is a "formula" to specify the model. A model is usually formed by the "~" operator. For a regression, we use y ~ x, which is interpreted as the outcome variable y is modelled by a linear predictor x. Therefore, for the regression analysis in this specific example, we use hvltt2 ~ hvltt.
The regression results are saved into an R object called regmodel. To show the basic results including the estimated regression intercept and slope, one can type the name of the object directly in the R console.
For more detailed results, the summary function can be applied to the regression object.
The estimated intercept is 5.1853 and the estimated slope is 0.7342. Their corresponding standard errors are 0.5463 and 0.200, respectively.
For testing the hypothesis that the slope is 0 -- \(H_0: \beta_1 = 0\). The t-statistic is 36.719. Based on the t distribution with the degrees of freedom 1573, we have the p-value < 2e-16. Therefore, one would reject the null hypothesis if the signifance level 0.05 is used.
Similarly, for testing the hypothesis that the intercept is 0 -- \(H_0: \beta_0 = 0\). The t-statistic is 9.492. Based on the t distribution with the degrees of freedom 1573, we have the p-value < 2e-16. Therefore, one would reject the null hypothesis.
The residual standard error is 3.951 and therefore, the estimated variance of the residual is \(\hat{\sigma}^2 = 3.951^2 = 15.61\).
> usedata("active")
>
> regmodel<-lm(hvltt2~hvltt, data=active)
> regmodel
Call:
lm(formula = hvltt2 ~ hvltt, data = active)
Coefficients:
(Intercept) hvltt
5.1854 0.7342
>
> summary(regmodel)
Call:
lm(formula = hvltt2 ~ hvltt, data = active)
Residuals:
Min 1Q Median 3Q Max
-14.6671 -2.5408 0.2565 2.7250 13.5987
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.1853 0.5463 9.492 <2e-16 ***
hvltt 0.7342 0.0200 36.719 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.951 on 1573 degrees of freedom
Multiple R-squared: 0.4615, Adjusted R-squared: 0.4612
F-statistic: 1348 on 1 and 1573 DF, p-value: < 2.2e-16
>
Coefficient of Determination (Multiple R-squared)
Significant tests show if a linear relationship exists but not the strength of the relationship. The coefficient of determination, \(R^2\), is a descriptive measure of the strength of the regression relationship, a measure on how well the regression line fits the data. In general the higher the value of \(R^2\), the better the model fits the data.
\(R^2 = 1\): Perfect match between the line and the data points.
\(R^2 = 0\): There are no linear relationship between x and y.
\(R^2\) is an effect size measure. Cohen (1988) defined some standards for interpreting \(R^2\).
\(R^2 = .01\): Small effect
\(R^2 = .06\): Medium effect
\(R^2 = .15\): Large effect.
For the regression example, the \(R^2 = 0.4615\), representing a large effect.
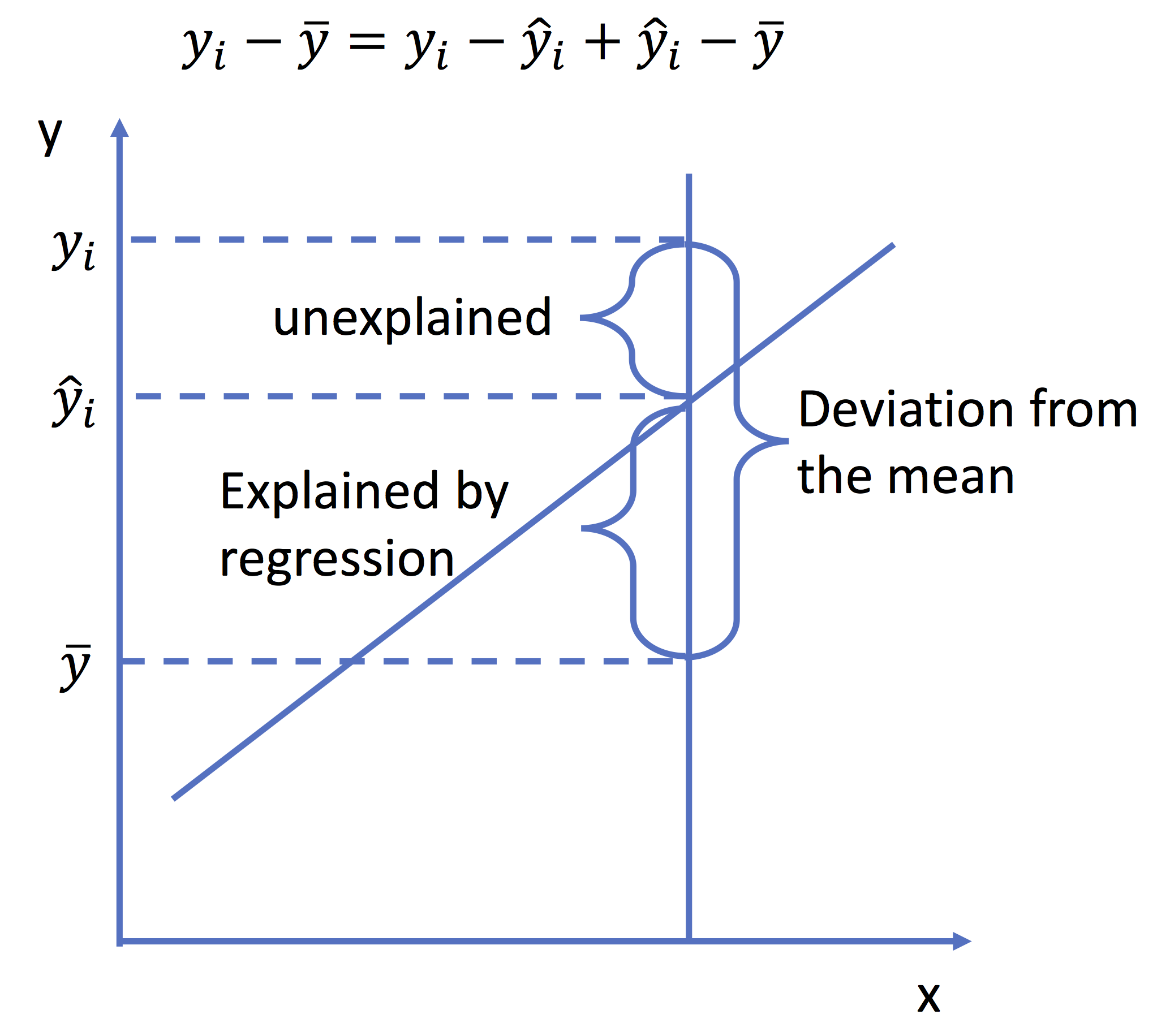
Calculation and interpretation of \(R^2\)
Simply speaking, the \(R^2\) tells the percentage of variance in \(y\) that can be explained by the regression model or by \(x\).
To cite the book, use:
Zhang, Z. & Wang, L. (2017-2026). Advanced statistics using R. Granger, IN: ISDSA Press. https://doi.org/10.35566/advstats. ISBN: 978-1-946728-01-2. To take the full advantage of the book such as running analysis within your web browser, please subscribe.