Mediation Analysis
Path diagrams
Consider a bivariate relationship between X and Y. If X is a predictor and Y is the outcome, we can fit a regression model
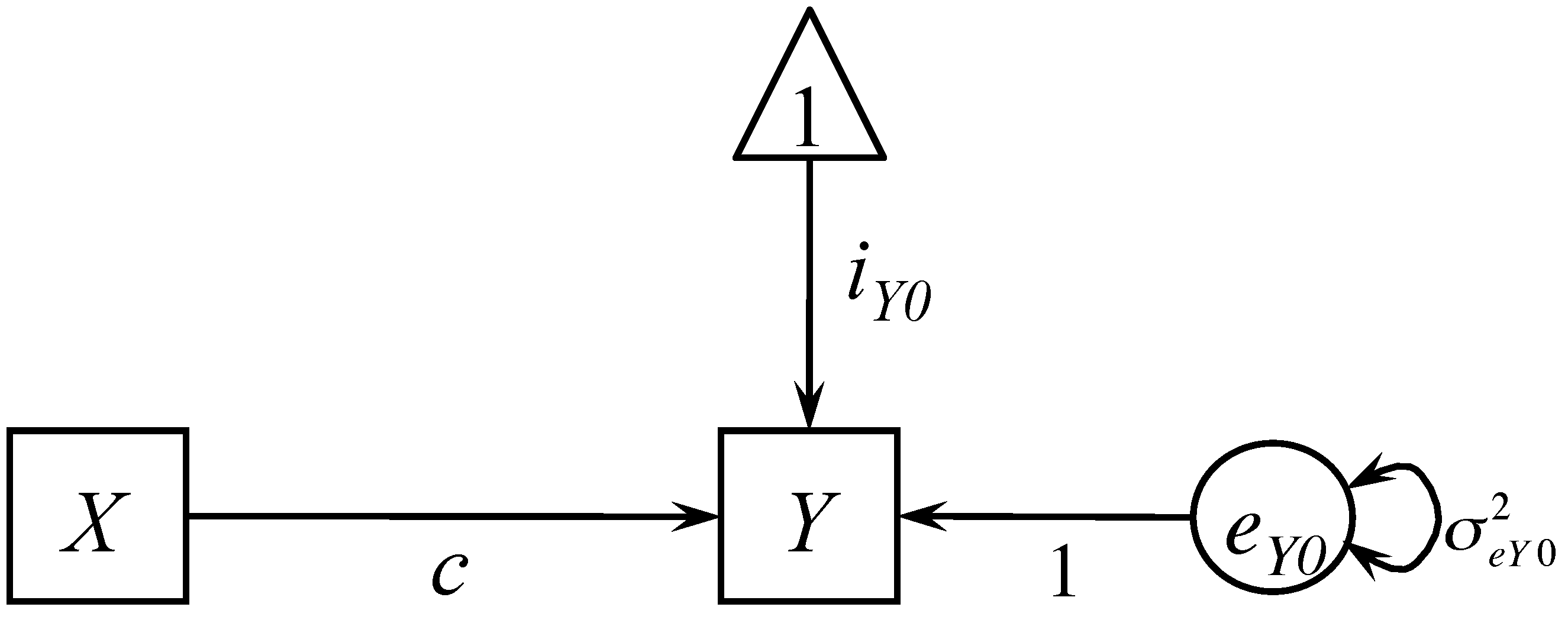
\[Y=i_{Y0}+cX+e_{Y0}\]
where $c$ is the effect of $X$ on $Y$, also called as the total effect of $X$ on $Y$. The model can be expressed as a path diagram as shown below.
Rules to draw a path diagram
In a path diagram, there are three types of shapes: a rectangle, a circle, and a triangle, as well as two types of arrows: one-headed (single-headed) arrow and two-headed (double-headed) arrows.
A rectangle represents an observed variable, which is a variable in the dataset with known information from the subjects. A circle or elliptical represents an unobserved variable, which can be the residuals, errors, or factors. A triangle, typically with 1 in it, represents either an intercept or a mean.
A one-headed arrow means that the variable on the side without the arrow predicts the variable on the side with the arrow. If the two-headed arrow is on a single variable, it represents a variance. If the two-headed arrow is between two variables, it represents the covariance between the two variables.
How to draw path diagrams?
Many different software can be used to draw path diagrams such as Powerpoint, Word, OmniGaffle, ect. For the ease of use, we recommend the online program WebSEM (https://websem.psychstat.org), which allows researchers to do SEM online, even on a smart phone. In addition, the drawn path diagram can be estimated using the uploaded/provided data (WebSEM). A simpler version of such program can be found at http://semdiag.psychstat.org.
What is mediation or what is a mediator?
In the classic paper on mediation analysis, Baron and Kenny (1986, p.1176) defined a mediator as "In general, a given variable may be said to function as a mediator to the extent that it accounts for the relation between the predictor and the criterion. " Therefore, mediation analysis answers the question why X can predict Y.
Suppose the effect of X on Y may be mediated by a mediating variable M. Then, we can write a mediation model as two regression equations
\begin{eqnarray*} M & = & i_{M}+aX+e_{M} \\ Y & = & i_{Y}+c'X+bM+e_{Y}. \end{eqnarray*}
This is the simplest but most popular mediation model. $c'$ is called the direct effect of X on Y with the inclusion of variable M. The indirect effect or mediation effect is $a*b$, the effect of X on Y through M. The total effect of X on Y is $c=c\prime+a*b$. This simple mediation model can also be portrayed as a path diagram shown below.
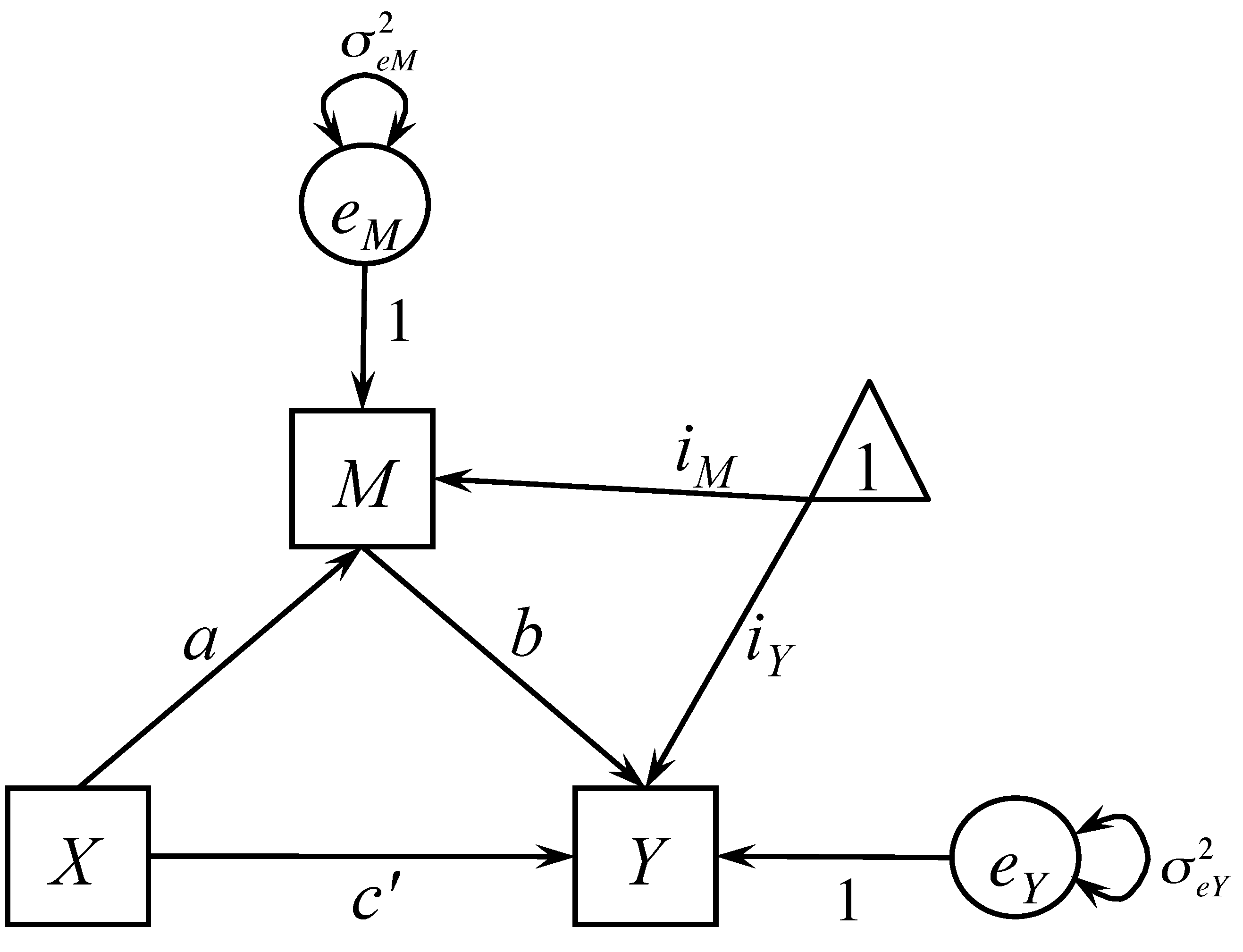
Note that a mediation model is a directional model. For example, the mediator is presumed to cause the outcome and not vice versa. If the presumed model is not correct, the results from the mediation analysis are of little value. Mediation is not defined statistically; rather statistics can be used to evaluate a presumed mediation model.
Mediation effects
The amount of mediation, which is called the indirect effect, is defined as the reduction of the effect of the input variable on the outcome, $c-c'$. $c-c' = ab$ when (1) multiple regression (or structural equation modeling without latent variables) is used, (2) there are no missing data, and (3) the same covariates are in the equations if there are any covariates. However, the two are only approximately equal for multilevel models, logistic analysis and structural equation models with latent variables. In this case, we calculate the total effect via $c'+ab$ instead of $c$. For the simplest mediation model without missing data, $ab=c-c'$.
Testing mediation effects
An example
We use the following example to show how to conduct mediation analysis and test mediation effects.
Research has found that parents' education levels can influence adolescent mathematics achievement directly and indirectly. For example, Davis-Kean (2005) showed that parents' education levels are related to children's academic achievement through parents' beliefs and behaviors. To test a similar hypothesis, we investigate whether home environment is a mediator in the relation between mothers' education and children's mathematical achievement. Data used in this example are from the National Longitudinal Survey of Youth, the 1979 cohort (NLSY79, for Human Resource Research, 2006). Data were collected in 1986 from N=371 families on mothers' education level (ME), home environment (HE), and children's mathematical achievement (Math). For the mediation analysis, mothers' education is the input variable, home environment is the mediator, and children's mathematical achievement is the outcome variable. Using a path diagram, the involved mediation model is given below.
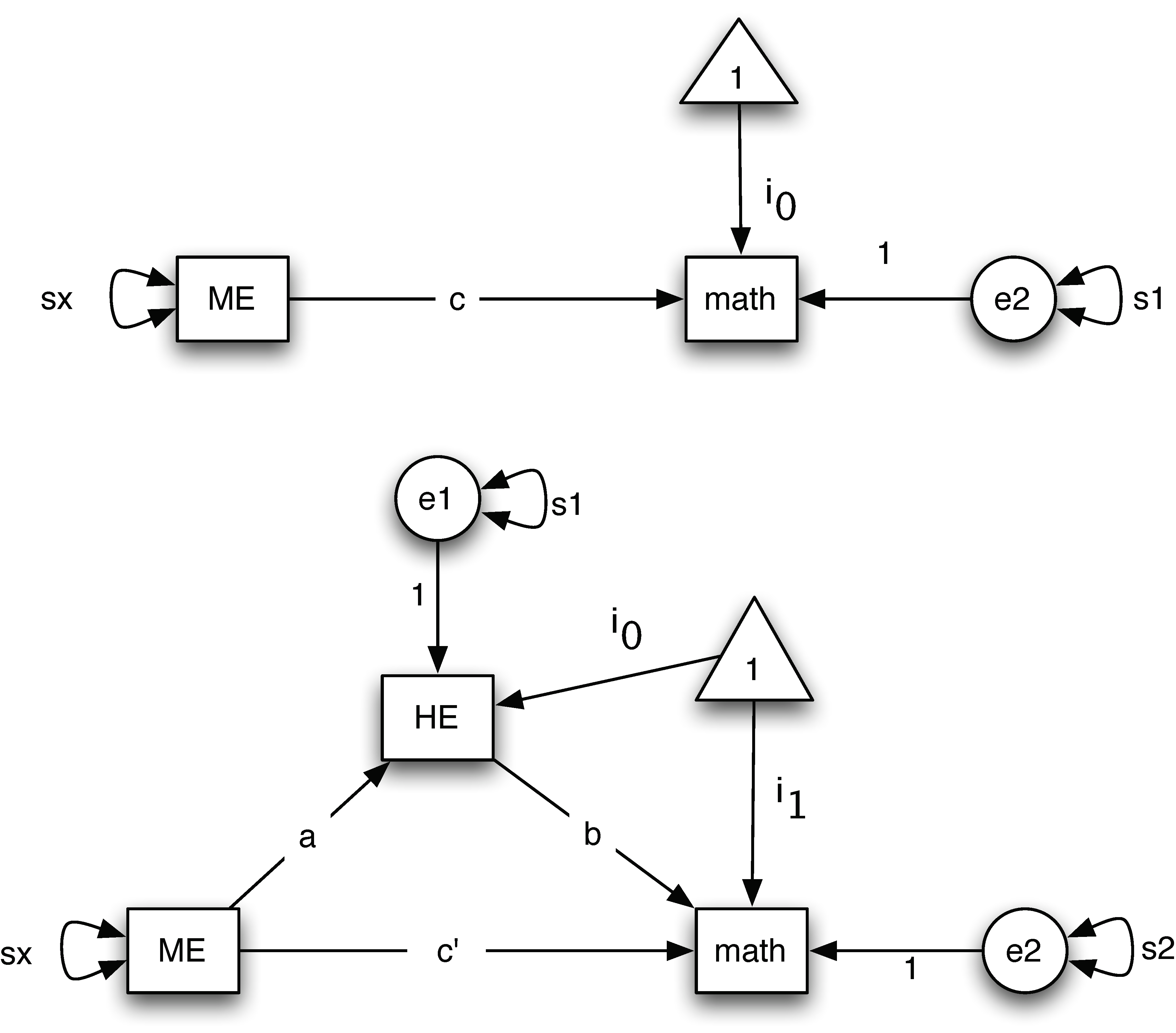
Baron and Kenny (1986) method
Baron and Kenny (1989) outlined a 4-step procedure to determine whether there is a mediation effect.
- Show that X is correlated with Y. Regress Y on X to estimate and test the path $c$. This step establishes that there is an effect that may be mediated.
- Show that X is correlated with M. Regress M on X to estimate and test path \(a\). This step essentially involves treating the mediator as if it were an outcome variable.
- Show that M affects Y. Regress Y on both X and M to estimate and test path \(b\). Note that it is not sufficient just to correlate the mediator with the outcome; the mediator and the outcome may be correlated because they are both caused by the input variable X. Thus, the input variable X must be controlled in establishing the effect of the mediator on the outcome.
- To establish that M completely mediates the X-Y relationship, the effect of X on Y controlling for M (path $c'$) should be zero. The effects in both Steps 3 and 4 are estimated in the same equation.
If all four of these steps are met, then the data are consistent with the hypothesis that variable M completely mediates the X-Y relationship, and if the first three steps are met but the Step 4 is not, then partial mediation is indicated.
The R code for the 4-step method for the example data is shown below.
> usedata('nlsy'); attach(nlsy);
>
> # Step 1
> summary(lm(math~ME))
Call:
lm(formula = math ~ ME)
Residuals:
Min 1Q Median 3Q Max
-14.6224 -2.9299 -0.4574 2.4876 29.4876
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.1824 1.3709 4.510 8.73e-06 ***
ME 0.5275 0.1199 4.398 1.43e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.618 on 369 degrees of freedom
Multiple R-squared: 0.04981, Adjusted R-squared: 0.04723
F-statistic: 19.34 on 1 and 369 DF, p-value: 1.432e-05
>
> # Step 2
> summary(lm(HE~ME))
Call:
lm(formula = HE ~ ME)
Residuals:
Min 1Q Median 3Q Max
-5.5020 -0.7805 0.2195 1.2195 3.3587
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.10944 0.49127 8.365 1.25e-15 ***
ME 0.13926 0.04298 3.240 0.0013 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.655 on 369 degrees of freedom
Multiple R-squared: 0.02766, Adjusted R-squared: 0.02502
F-statistic: 10.5 on 1 and 369 DF, p-value: 0.001305
>
> # Step 3 & 4
> summary(lm(math~ME+HE))
Call:
lm(formula = math ~ ME + HE)
Residuals:
Min 1Q Median 3Q Max
-14.9302 -3.0045 -0.2226 2.2386 29.3856
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.2736 1.4764 2.895 0.004022 **
ME 0.4628 0.1201 3.853 0.000137 ***
HE 0.4645 0.1434 3.238 0.001311 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.559 on 368 degrees of freedom
Multiple R-squared: 0.07613, Adjusted R-squared: 0.07111
F-statistic: 15.16 on 2 and 368 DF, p-value: 4.7e-07
>
In Step 1, we fit a regression model using ME as the predictor and math as the outcome variable. Based on this analysis, we have $\hat{c}$ =.5275 (t = 4.298, p <.001) and thus ME is significantly related to math. Therefore, Step 1 is met: the input variable is correlated with the outcome.
In Step 2, we fit a regression model using ME as the predictor and HE as the outcome variable. From this analysis, we have $\hat{a}$ = .139 (t = 3.24, p = .0013) and thus ME is significantly related to HE. Therefore, Step 2 is met: the input variable is correlated with the mediator.
In Step 3, we fit a multiple regression model with ME and HE as predictors and math as the outcome variable. For the analysis, we have $\hat{b}$=.4645 (t = 3.238, p =.0013). Because both $\hat{a}$ and $\hat{b}$ are significant, we can say HE significantly mediates the relationship between ME and math. The mediation effect estimate is $\hat{ab}=.139{*}.4645=0.065$.
Step 4, from the results in Step 3, we know that the direct effect c' ($\hat{c'}$=.4628, t = 3.853, p = .00013) is also significant. Thus, there exists a partial mediation.
Sobel test
Many researchers believe that the essential steps in establishing mediation are Steps 2 and 3. Step 4 does not have to be met unless the expectation is for complete mediation. In the opinion of most researchers, though not all, Step 1 is not required. However, note that a path from the input variable to the outcome is implied if Steps 2 and 3 are met. If $c'$ were in the opposite sign to that of $ab$, then it could be the case that Step 1 would not be met, but there is still mediation. In this case the mediator acts like a suppressor variable. MacKinnon, Fairchild, and Fritz (2007) called it inconsistent mediation. For example, consider the relationship between stress and mood as mediated by coping. Presumably, the direct effect is negative: more stress, the worse the mood. However, likely the effect of stress on coping is positive (more stress, more coping) and the effect of coping on mood is positive (more coping, better mood), making the indirect effect positive. The total effect of stress on mood then is likely to be very small because the direct and indirect effects will tend to cancel each other out. Note that with inconsistent mediation, the direct effect is typically larger than the total effect.
It is therefore much more common and highly recommended to perform a single test of $ab$, than the two seperate tests of $a$ and $b$. The test was first proposed by Sobel (1982) and thus is also called the Sobel test. The standard error estimate of $\hat{a}$ is denoted as $s_{\hat{a}}$ and the standard error estimate of $\hat{b}$ is denoted as $s_{\hat{b}}$. The Sobel test used the following standard error estimate of $\hat{ab}$
\[ \sqrt{\hat{b}^{2}s_{\hat{a}}^{2}+\hat{a}^{2}s_{\hat{b}}^{2}}.\]
The test of the indirect effect is given by dividing $\hat{ab}$ by the above standard error estimate and treating the ratio as a Z test:
\[ z-score=\frac{\hat{ab}}{\sqrt{\hat{b}^{2}s_{\hat{a}}^{2}+\hat{a}^{2}s_{\hat{b}}^{2}}}.\]
If a z-score is larger than 1.96 in absolute value, the mediation effect is significant at the .05 level.
From the example in the 4-step method, the mediation effect is $\hat{ab}$=0.065 and its standard error is
\[\sqrt{\hat{b}^{2}s_{\hat{a}}^{2}+\hat{a}^{2}s_{\hat{b}}^{2}} = \sqrt{.4645^{2}*.043^{2}+.139^{2}*.1434^{2}}=.028.\]
Thus,
\[z-score=\frac{.065}{.028}=2.32.\]
Because the z-score is greater than 1.96, the mediation effect is significant at the alpha level 0.05. Actually, the p-value is 0.02.
The Sobel test is easy to conduct but has many disadvantages. The derivation of the Sobel standard error estimate presumes that $\hat{a}$ and $\hat{b}$ are independent, something that may not be true. Furthermore, the Sobel test assumes $\hat{ab}$ is normally distributed and might not work well for small sample sizes. The Sobel test has also been shown to be very conservative and thus the power of the test is low. One solution is to use the bootstrap method.
Bootstrapping for mediation analysis
The bootstrap method was first employed in the mediation analysis by Bollen and Stine (1990). This method has no distribution assumption on the indirect effect $\hat{ab}$. Instead, it approximates the distribution of $\hat{ab}$ using its bootstrap distribution. The bootstrap method was shown to be more appropriate for studies with sample sizes 20-80 than single sample methods. Currently, the bootstrap method of mediation is generally following the procedure used in Bollen and Stine (1990).
The method works in the following way. Using the original data set (Sample size = n) as the population, draw a bootstrap sample of n individuals with paired (Y, X, M) scores randomly from the data set with replacement. From the bootstrap sample, estimate $ab$ through some method such as OLS based on a set of regression models. Repeat the two steps for a total of B times. B is called the number of bootstraps. The empirical distribution based on this bootstrap procedure can be viewed as the distribution of $\hat{ab}$. The $(1-\alpha)*100\%$ confidence interval of $ab$ can be constructed using the $\alpha/2$ and $1-\alpha/2$ percentiles of the empirical distribution.
In R, mediation analysis based on both Sobel test and bootstrapping can be conducted using the R bmem() package. For example, the R code for Sobel test is given below.
> library(bmem)
Loading required package: Amelia
Loading required package: Rcpp
##
## Amelia II: Multiple Imputation
## (Version 1.8.1, built: 2022-11-18)
## Copyright (C) 2005-2023 James Honaker, Gary King and Matthew Blackwell
## Refer to http://gking.harvard.edu/amelia/ for more information
##
Loading required package: MASS
Loading required package: snowfall
Loading required package: snow
> library(sem)
> usedata('nlsy')
>
> nlsy.model<-specifyEquations(exog.variances=T)
1: math = b*HE + cp*ME
2: HE = a*ME
3:
Read 2 items
NOTE: adding 3 variances to the model
> effects<-c('a*b', 'cp+a*b')
> nlsy.res<-bmem.sobel(nlsy, nlsy.model,effects)
Estimate S.E. z-score p.value
b 0.46450283 0.14304860 3.247168 1.165596e-03
cp 0.46281480 0.11977862 3.863918 1.115825e-04
a 0.13925694 0.04292438 3.244239 1.177650e-03
V[HE] 2.73092635 0.20078170 13.601471 0.000000e+00
V[math] 20.67659134 1.52017323 13.601471 0.000000e+00
V[ME] 4.00590078 0.29451968 13.601471 0.000000e+00
a*b 0.06468524 0.02818457 2.295059 2.172977e-02
cp+a*b 0.52750005 0.11978162 4.403848 1.063474e-05
>
> dset <- read.table('https://nd.psychstat.org/_media/classdata/active.mediation.txt', header=F)
>
Note that to use the package, we need to specify the mediation model first. The mediation model can be provided using equations. For the simple mediation model, there need two regression equation: math = b*HE + cp*ME and HE = a*ME. Clearly, the outcome variable is on the left of the "=" sign. In addition, we should include the parameter labels in the model. For example, a, b, and cp represent the parameters in the model. The function to specify the model is specifyEquations(), which is a function of the R package bmem(), which bmem() was developed based on. In this function, we also use the option exog.variances=T, which is used to specify the variance parameters automatically.
In addition to the model, we also need to provide the indirect effects or any other effects of interest. Multiple effects can be provided using a vector. Each effect is a combination of multiple model parameters. For example, a*b is the mediation effect and a*b + cp is the total effect.
Finally, the function bmem.sobel() is used to conduct the Sobel test. The function requires at least three options: a data set, a model, and the effects of interest, in the order presented.
The output includes the parameter estimate, standard error, z-score and p-value for each parameter and effect under investigation. Note that the mediation effect is again 0.065 and is significant at the alpha level 0.05.
Conducting a bootstrap is similar to Sobel test. In this case, the function bmem() is used. In addition to provide a data set, a model, and the effects of interest, we can also specify how many bootstrap samples are used (the option boot=). The default is 1,000. In this example, we used 500.
The output includes the 95% bootstrap CIs. Using a CI, we can conduct a test. Based on the fact that the CI for ab [.0258, .1377] does not include 0, there is a significant mediation effect. In addition, because the CI for $c'$ does not contain 0, $c'$ is significantly different from 0. Thus, we have a partial mediation effect.
> library(bmem)
Loading required package: Amelia
Loading required package: Rcpp
##
## Amelia II: Multiple Imputation
## (Version 1.8.1, built: 2022-11-18)
## Copyright (C) 2005-2023 James Honaker, Gary King and Matthew Blackwell
## Refer to http://gking.harvard.edu/amelia/ for more information
##
Loading required package: MASS
Loading required package: snowfall
Loading required package: snow
> library(sem)
> usedata('nlsy')
>
> nlsy.model<-specifyEquations(exog.variances=T)
1: math = b*HE + cp*ME
2: HE = a*ME
3:
Read 2 items
NOTE: adding 3 variances to the model
> effects<-c('a*b', 'cp+a*b')
> nlsy.res<-bmem(nlsy, nlsy.model,effects, boot=500)
The bootstrap confidence intervals for parameter estimates
estimate se.boot 2.5% 97.5%
b 0.46450283 0.13262762 0.21610651 0.7194799
cp 0.46281480 0.12254006 0.19073858 0.6798118
a 0.13925694 0.04100424 0.06039890 0.2135725
V[HE] 2.72356536 0.20749414 2.35776710 3.2096779
V[math] 20.62085929 2.92209075 16.22589274 27.6936804
V[ME] 3.99510320 0.40327643 3.32160165 4.9247955
a*b 0.06468524 0.02589075 0.02462289 0.1224241
cp+a*b 0.52750005 0.12359351 0.27831908 0.7587316
The bootstrap confidence intervals for model fit indices
estimate se.boot 2.5% 97.5%
chisq 3.28626e-13 2.794524e-13 0 6.57252e-13
GFI NA NA NA NA
AGFI NA NA NA NA
RMSEA NA NA NA NA
NFI NA NA NA NA
NNFI NA NA NA NA
CFI NA NA NA NA
BIC 3.28626e-13 2.794524e-13 0 6.57252e-13
SRMR NA NA NA NA
The literature has suggested the use of Bollen-Stine bootstrap for model fit. To do so, use the function bmem.bs().
>
To cite the book, use:
Zhang, Z. & Wang, L. (2017-2026). Advanced statistics using R. Granger, IN: ISDSA Press. https://doi.org/10.35566/advstats. ISBN: 978-1-946728-01-2.
To take the full advantage of the book such as running analysis within your web browser, please subscribe.